单词列表是许多领域的大量研究的基础。Complexity Science Hub 的研究人员现已开发出一种算法,可以应用于不同的语言,并且可以比其他算
单词列表是许多领域的大量研究的基础。Complexity Science Hub 的研究人员现已开发出一种算法,可以应用于不同的语言,并且可以比其他算法更好地扩展单词列表。
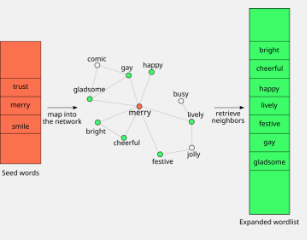
许多项目都是从创建单词列表开始的。不仅在创建思维导图的公司中,而且在所有研究领域中。想象一下,您想通过分析 Twitter 帖子来了解人们在哪几天心情特别好。仅仅寻找“快乐”这个词是不够的。
相反,您将不得不使用一种算法来检测所有表明某人快乐的推文。“因此,第一步是创建一个包含所有表明这一点的词的列表。整个研究都是这样做的,”维也纳复杂性科学中心的研究员Anna Di Natale解释道。但是如何得出最准确、最完整的单词列表呢?
许多人都关心的问题
这个普遍存在的问题不仅涉及想要了解公众如何接受政客言论的舆论研究人员。公司也想通过情绪分析了解他们的产品是如何被感知的。
为了改进,Di Natale 现在开发了一种新方法,称为 LEXpander,其性能优于以前的算法。这甚至是两种不同的语言——德语和英语。此外,有史以来第一次,她开发了一种完全可以比较不同工具的方法。
改进的性能
与其他四种词表扩展算法(WordNet、Empath 2.0、FastText 和 GloVe)相比,LEXpander 的表现要好得多,尤其是在德语中。例如,研究人员发现,LEXpander 在扩展英语单词列表以获得积极意义时,猜对了 43% 的单词。相比之下,一个非常流行的模型 FastText 只有 28% 的时间是正确的。
独立于语言本身
原因是该工具独立于语言工作。它不是基于一种语言,而是基于所谓的 colexification 网络。这一公认的语言概念基于同音异义词和多义词,即具有两个或更多不同含义的单个词。例如:古希腊词 φìρμακον (pharmacon) 可以表示药物或毒药。两件不同的事情,但主题很接近。但还有其他一些并不暗示亲属关系——例如作为金融机构的“银行”或河流沿岸的土地。
“如果你用多种语言收集它们——在这里我们分析了大约 19 种不同的语言——你可以看到它们之间的联系,”Di Natale 说。当这些并置化以跨不同语系的多种语言发生时,网络就形成了,从而建立了联系。
这种与语言本身的独立性使得 LEXpander 在不同语言中都能取得更好的效果。“有许多针对英语开发的方法。它们工作得非常好,而且很快,每个人都在使用它们。尝试将它们应用到其他语言上是可行的,但如果你已经开始为德语或意大利语开发方法可能效果不佳,”迪纳塔莱解释道。
声明本站所有作品图文均由用户自行上传分享,仅供网友学习交流。若您的权利被侵害,请联系我们